
机器学习算法(四)—— 集成学习

AI-摘要
Chat GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
机器学习算法(四)—— 集成学习
三水番1 集成学习
1.1 集成学习思想
- Bagging(随机森林)

- Boosting(AdaBoost、GBDT、XGBoost)
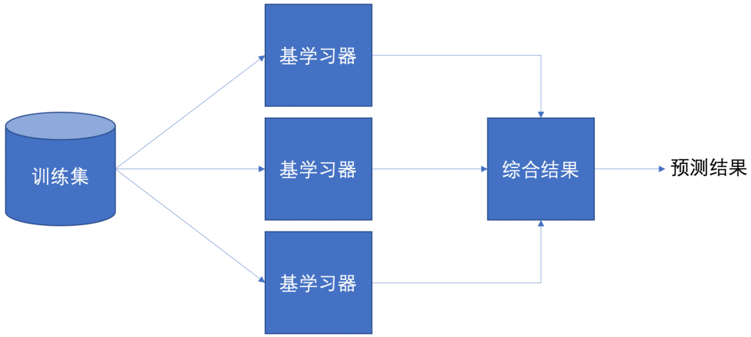
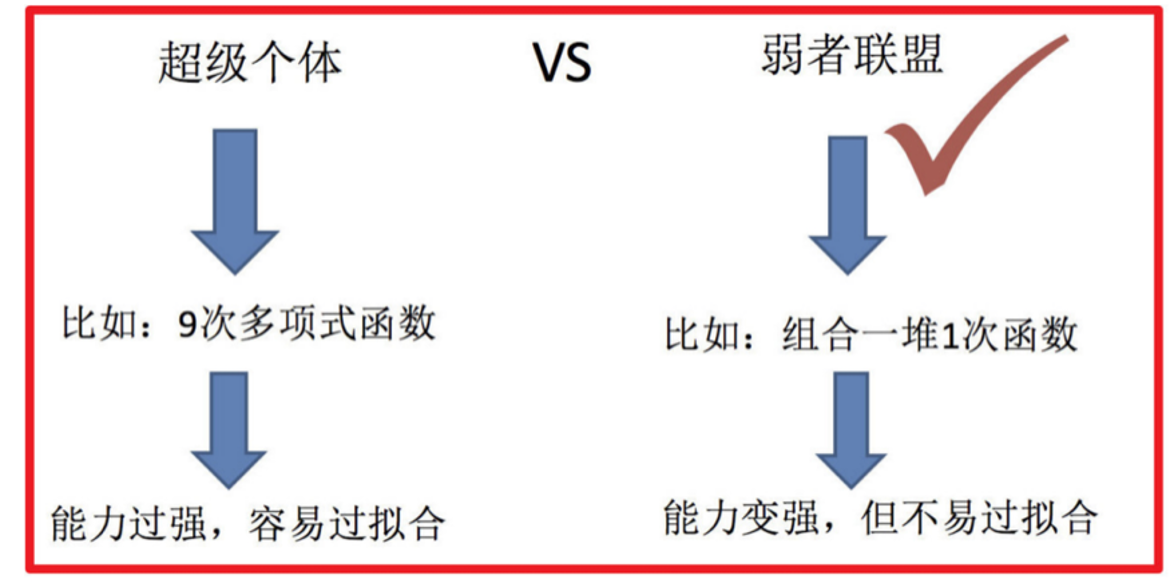
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(基学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
1.2 集成学习分类
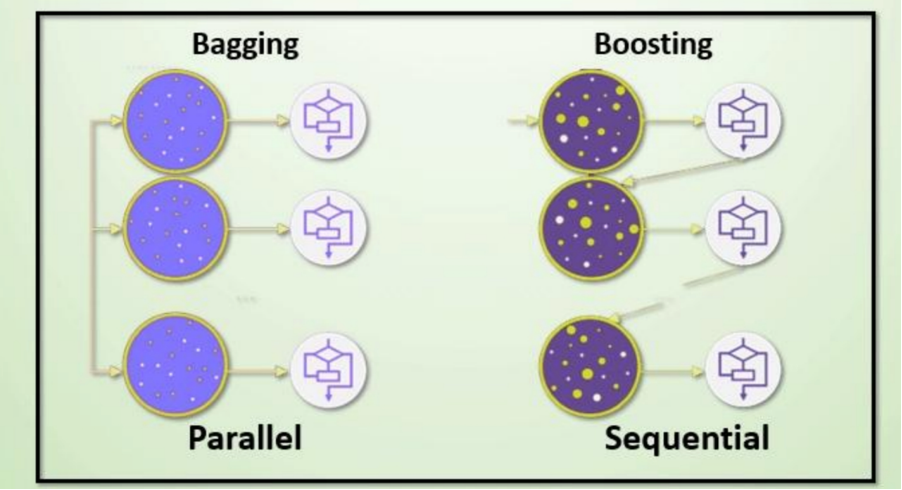
- Bagging:随机森林
- Boosting:Adaboost、GBDT、XGBoost、LightGBM
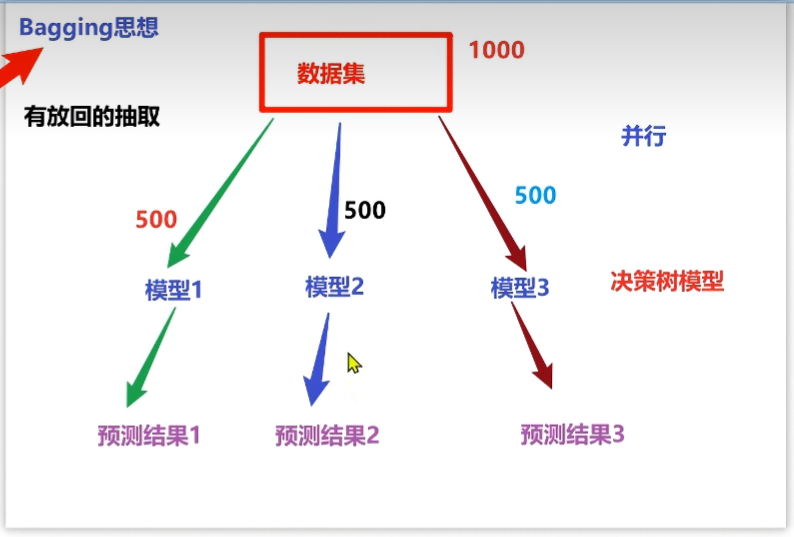
1.2.1 Bagging思想
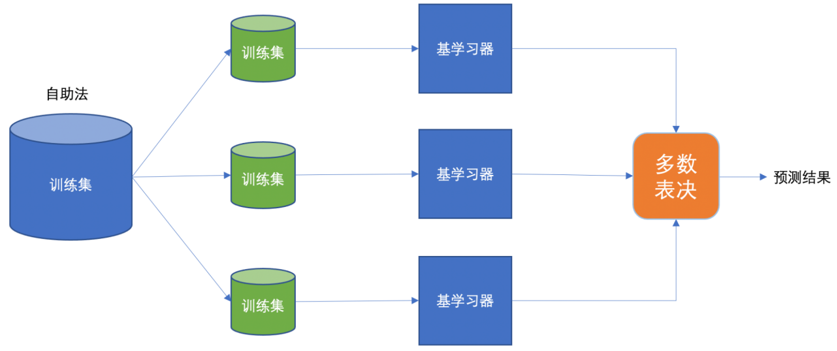
- 有放回的抽样(bootstrap抽样)产生不同的训练集,从而训练不同的学习器
- 通过平权投票、多数表决的方式决定预测结果
- 弱学习器可以并行训练
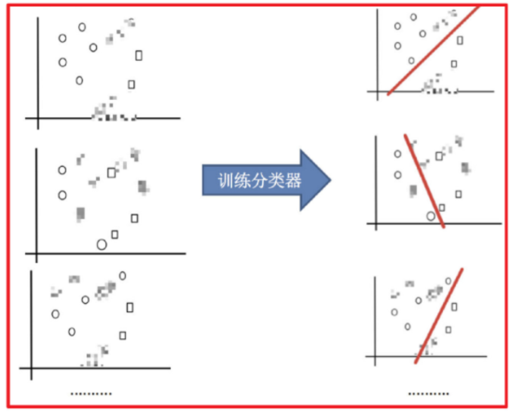
Bagging思想图
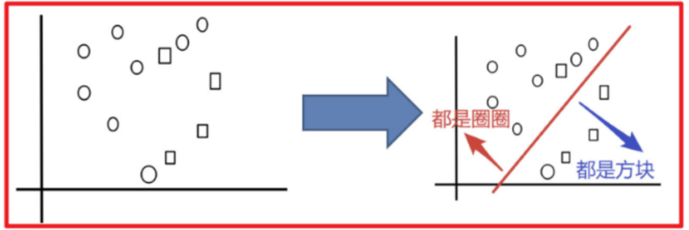
目标:把下图的圈和方块进行分类
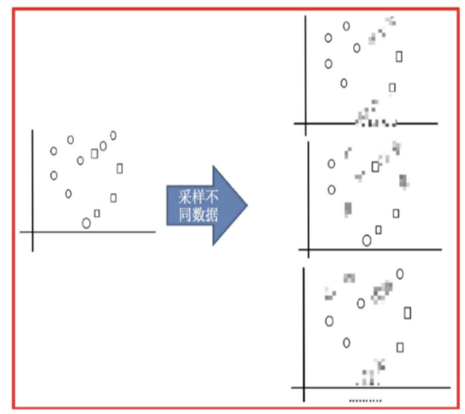
- 采样不同数据集
- 训练分类器
- 平权投票,获取最终结果
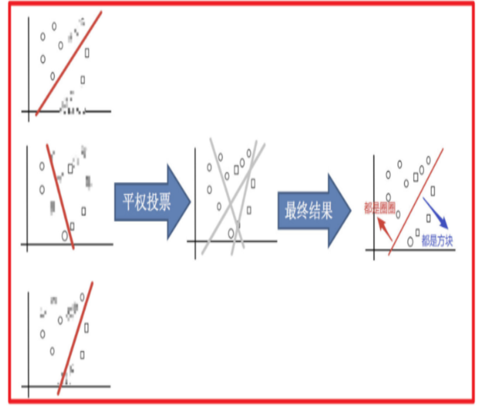
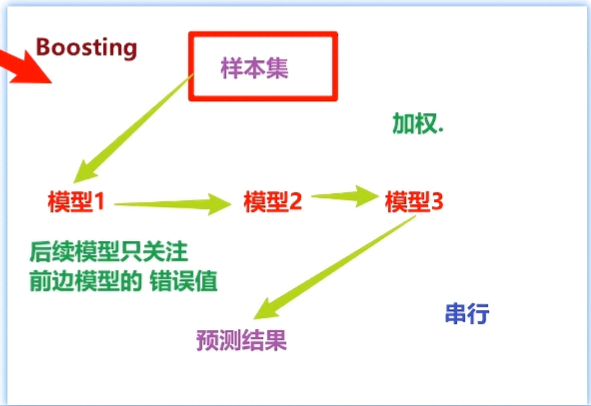
1.2.2 Boosting思想
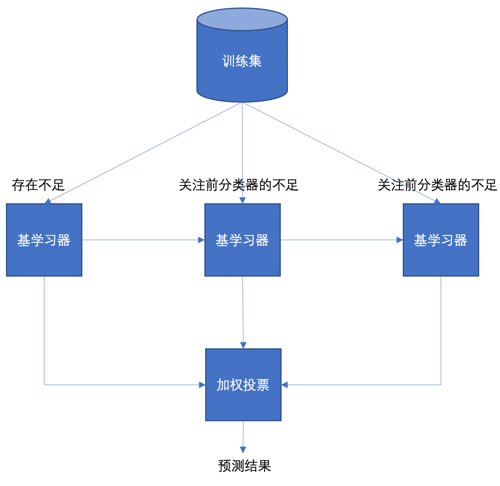
- 每一个训练器重点关注前一个训练器不足的地方进行训练
- 通过加权投票的方式,得出预测结果
- 串行的训练方式
Boosting思想生活中的举例
滚球兽→亚古兽→暴龙兽→机械暴龙兽→战斗暴龙兽

- 随着学习的积累从弱到强
- 每新加入一个弱学习器,整体能力就会得到提升
- 代表算法:Adaboost,GBDT,XGBoost,LightGBM
1.2.3 Bagging&Boosting对比

1.3 随机森林算法(Bagging)
随机森林是基于 Bagging 思想实现的一种集成学习算法,采用决策树模型作为每一个弱学习器。
- 训练:
- 有放回的产生训练样本
- 随机挑选 n 个特征(n 小于总特征数量)
- 预测:
- 平权投票,多数表决输出预测结果
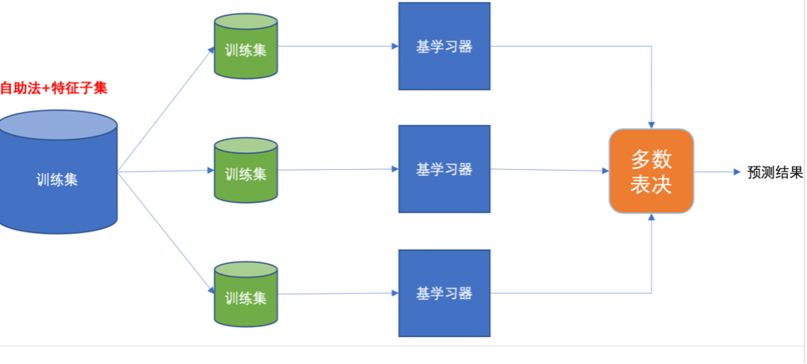
随机森林步骤 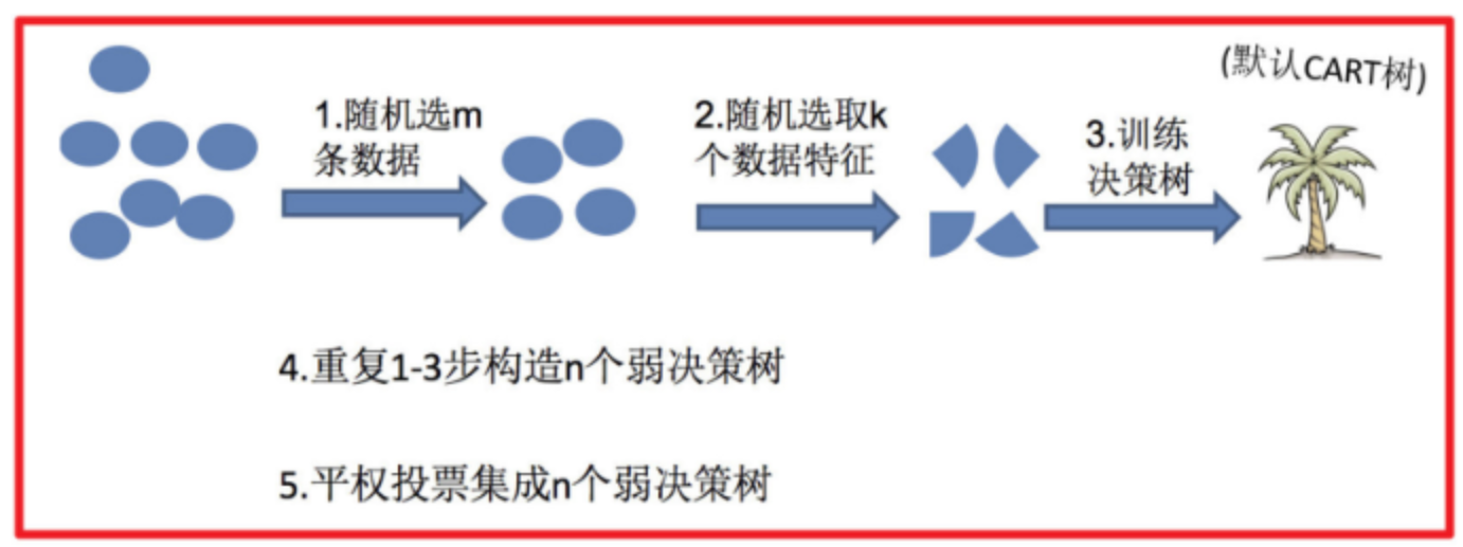
思考题
- 为什么要随机抽样训练集?
- 如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样。
- 为什么要有放回地抽样?
- 如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是
有偏的,也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。 - 综上:弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果
- 如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是
1.3.1 随机森林算法 – API
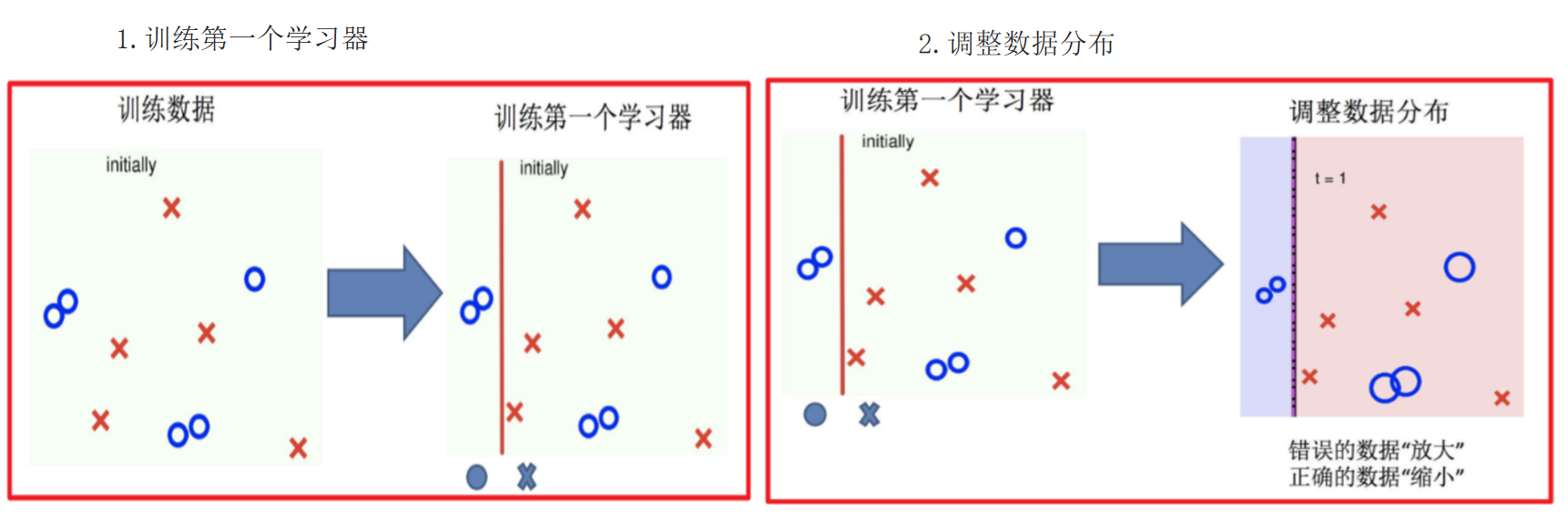
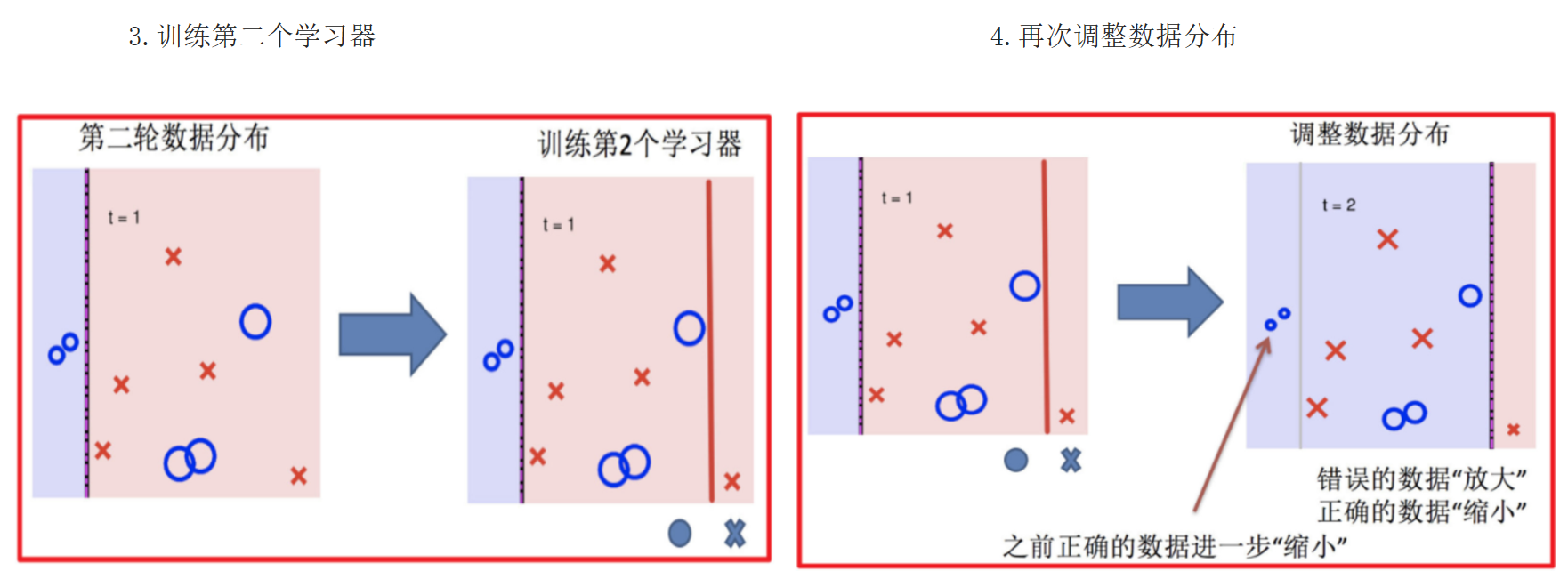
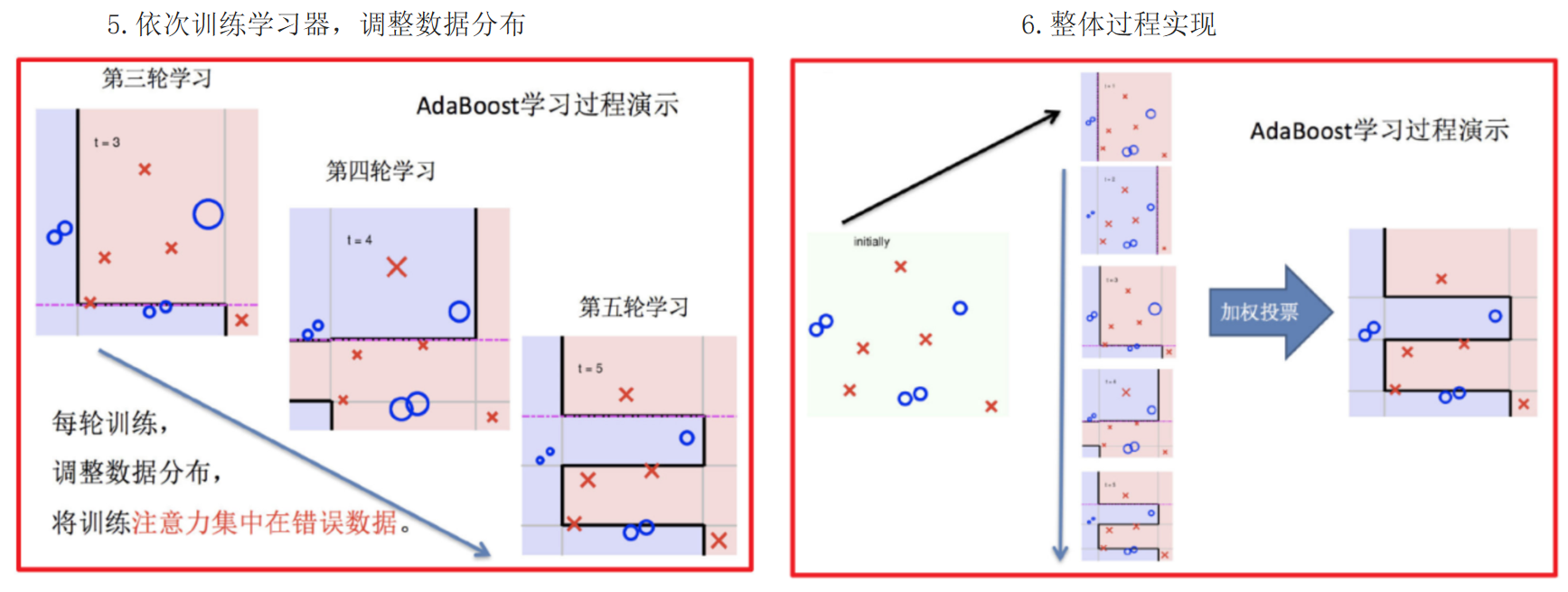
1.4 Adaboost算法
Adaptive Boosting(自适应提升)基于 Boosting思想 实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。








.png)
