
使用Zotero + Zotero Pdf2zh + Ollama使用本地自部署大模型作为 API 管理和翻译PDF文献

使用Zotero + Zotero Pdf2zh + Ollama使用本地自部署大模型作为 API 管理和翻译PDF文献
三水番最近在做论文阅读时,我想要一个「可控、低成本、隐私友好」的翻译工作流:
- 文献统一放在 Zotero 管理。
- 直接在右键菜单里翻译 PDF。
- 翻译模型尽量跑本地,不依赖国外在线服务。
最终我选择了这个插件:
这篇文章我会用尽量少的废话,带你从 0 跑通:
- Zotero PDF2zh 安装
- Python Server 启动
- 用 Ollama 作为 OpenAI 兼容 API
- 在 Zotero 内完成整篇论文翻译
效果图:
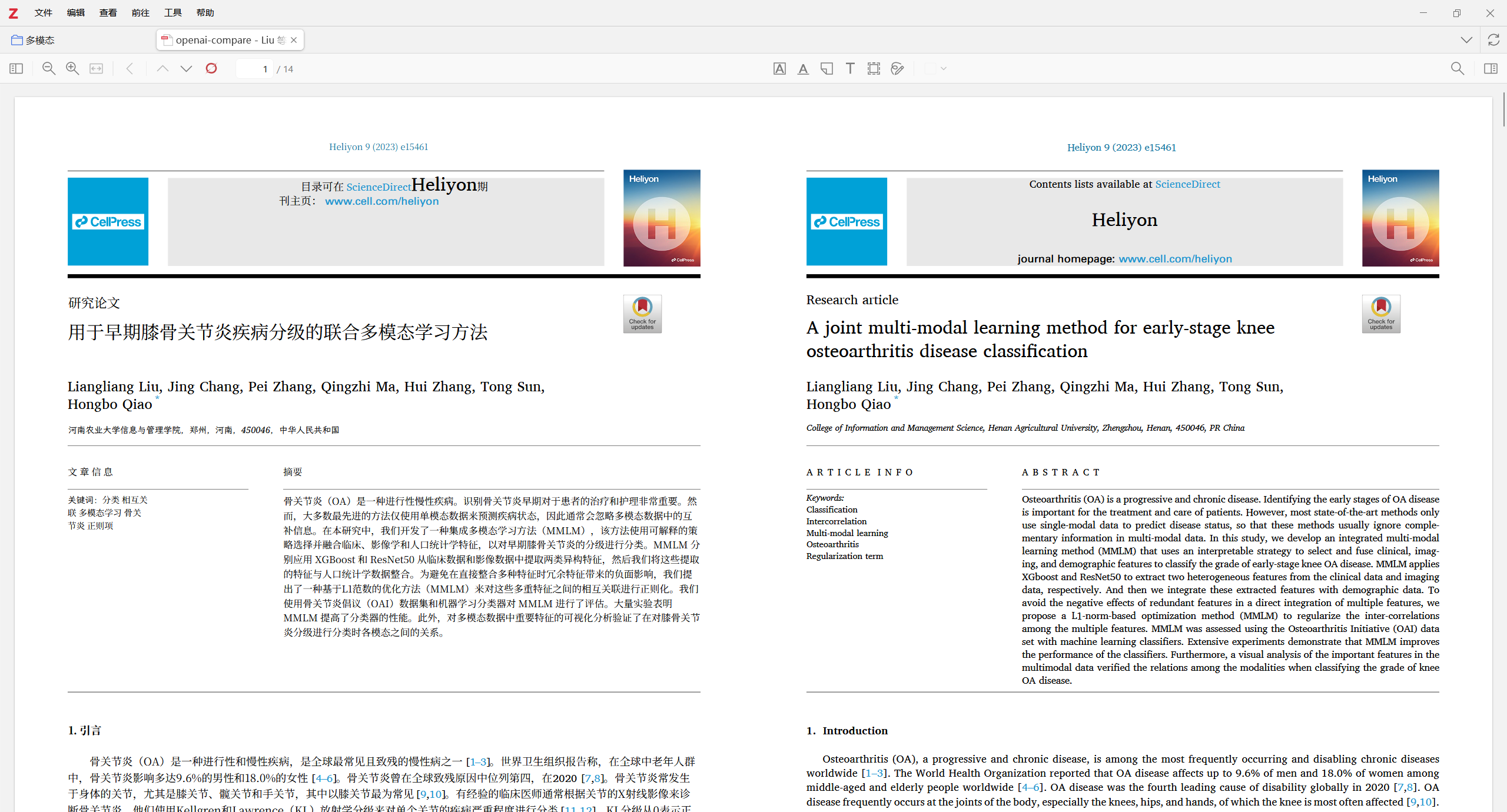
一、方案简介:为什么是这个组合
1. Zotero PDF2zh 负责什么
它本质上是 Zotero 插件 + 本地 Python 服务端:
- Zotero 端负责菜单、任务发起、附件管理
- server.py 负责真正的翻译任务调度
- 支持多种翻译后端(包括 OpenAI 兼容接口)
2. Ollama 负责什么
Ollama 提供本地模型推理能力。只要模型支持、机器配置够用,就可以:
- 本地翻译,不把正文发到第三方云服务
- 自己控制模型版本和参数
- 低成本反复试验
二、准备环境
建议先确认这几个前置条件:
- Zotero 已安装(7/8 均可)
- Python 3.12 可用
- Ollama 已安装并能正常运行
- 网络可访问 GitHub(用于拉取 server 与插件)
可以先在终端做最小检查:
1 | python --version |
如果你是 Windows,建议把项目放在非系统盘(如 D 盘),避免权限和路径问题。
三、安装 Zotero PDF2zh
1. 下载并启动 server
官方仓库里已经给了 server.zip,按这个流程最稳:
1 | mkdir zotero-pdf2zh && cd zotero-pdf2zh |
解压后目录应为:
1 | zotero-pdf2zh/ |
启动方式推荐两种(任选其一):
- uv(推荐)
- conda
我这里给出最常用命令:
1 | cd server |
或者 conda:
1 | cd server |
默认端口一般是 8890。
我写了个bat脚本方便启动:
1 | @echo off |
2. 安装 Zotero 插件(xpi)
从项目 Release 下载最新版 xpi(例如 v4.x):
- 打开 Zotero -> 工具 -> 插件
- 将 xpi 文件拖进去安装
- 必要时重启 Zotero
四、接入 Ollama 作为翻译 API
这一段是核心。
1. 启动 Ollama 服务并拉模型
先保证 Ollama 服务可用,然后拉一个中英文表现还不错的模型(示例):
1 | ollama pull qwen2.5:14b |
我的配置是:
- cpu: i5-12600kf
- gpu: 4070 12GB
- 内存: 32GB
如果你机器配置较低,可以先用更小的模型试跑。
2. 在 Zotero PDF2zh 里新增 OpenAI 兼容配置
进入 Zotero 的插件设置页面,找到 LLM API 配置管理,新增一条配置。
可参考以下填写:
- 服务类型:Ollama(或插件中 OpenAI 兼容项)
- Base URL:http://127.0.0.1:11434
- API Key:ollama(可填任意非空字符串)
- Model:qwen2.5:14b(与你实际拉取的模型名一致)
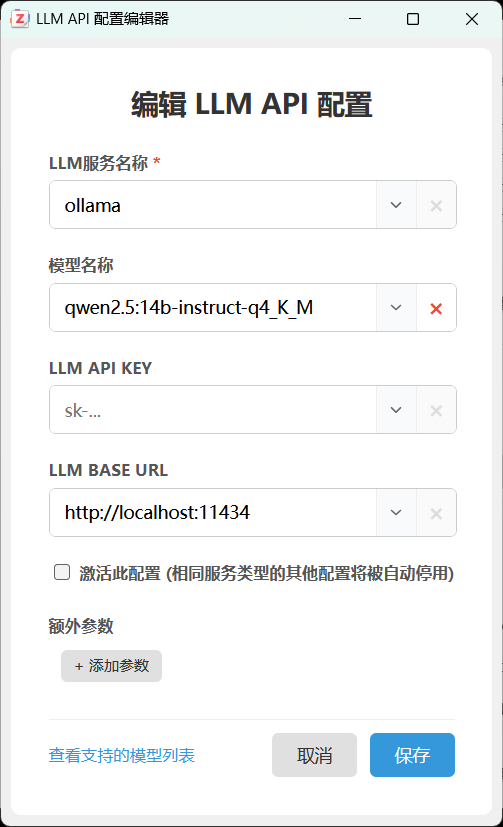
然后在底部「LLM API 配置管理」中选中你刚创建的配置。
注意:
- 只新增配置但不切换为当前服务时,翻译不会生效。
3. 并发参数建议
本地模型吞吐有限,建议先保守配置:
- qps:1-2
- pool size:2-4
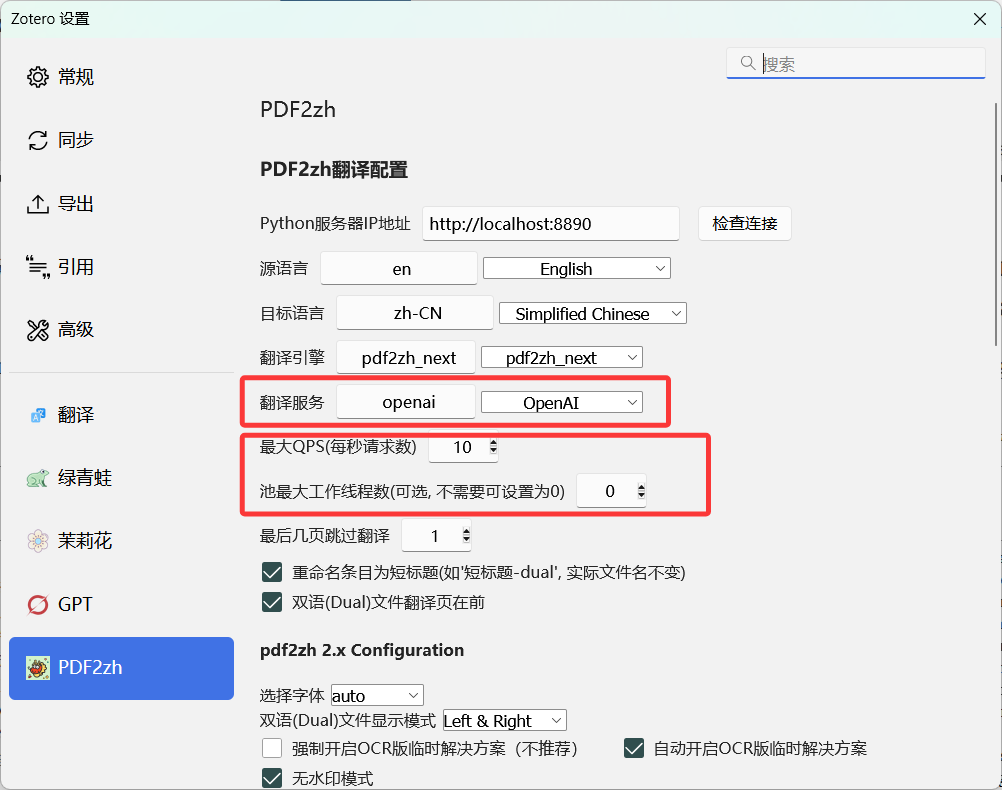
后续再根据 GPU/CPU 负载慢慢提高。
五、开始翻译一篇论文
在 Zotero 中选中文献条目或其 PDF,右键可看到 PDF2zh 菜单,常用选项有:
- 翻译 PDF:生成翻译版本
- 双语对照:生成原文与译文并排版本
- 裁剪 PDF:更适合手机阅读
我个人推荐流程:
- 先翻译 2-3 页小文档做参数验证。
- 确认模型和版式没问题后再跑长文。
- 首次跑完后再做并发调优。
六、效果与成本建议
1. 效果层面
本地模型翻译质量和模型大小、指令能力强相关:
- 小模型速度快,但术语稳定性可能一般
- 中大模型术语更稳,但耗时更高
如果你对术语一致性要求高,建议:
- 先固定一个模型长期使用
- 同一研究方向尽量不要频繁换模型
2. 成本层面
Ollama 本地方案的主要成本是硬件与时间:
- 优点:几乎没有 API 调用费用
- 缺点:首轮调参和速度优化需要耐心
七、常见问题排查
1. 检查连接失败
优先看三件事:
- server.py 是否仍在运行
- Zotero 中 Python Server IP 与端口是否一致
- 防火墙是否拦截本地端口
2. 翻译中途卡住
可能原因:
- 首次运行下载字体/资源较慢
- 模型过大导致本机推理吞吐不足
- 并发设置过高触发阻塞
处理建议:
- 先降并发再试
- 换小一档模型确认流程
- 先翻短文做健康检查
3. 扫描版 PDF 翻译质量差
扫描件需要先 OCR,再翻译。插件不是通用 OCR 替代品。
八、我的推荐配置(可直接抄)
如果你是个人电脑 + 本地模型新手,建议从这一组开始:
- 翻译引擎:pdf2zh_next
- API:OpenAI 兼容(Ollama)
- Base URL:http://127.0.0.1:11434 —– (/v1) -> 看情况加不加
- Model:qwen2.5:7b 或 qwen2.5:14b
- qps:1
- pool size:2
稳定后再逐步提高并发。
九、总结
Zotero PDF2zh + Ollama 这套组合,核心价值是:
- 在 Zotero 内一站式完成文献管理与翻译
- 本地模型可控,隐私更友好
- 成本低,适合长期科研阅读





.png)
